سلام و وقت بخیر
جدیداً دارم ابزار ایرفلو رو در یکی از شرکتها نصب و راهاندازی میکنم. با خودم گفتم بیام و چند جلسه آموزشی برای علاقهمندان به این حوزه آماده کنم. در این سلسله پست که امروز جلسه اولش رو مینویسم، قراره باهم همه چیز رو در مورد ایرفلو با زبان خیلی ساده و در عین حال کاربردی یاد بگیریم و سعی میکنم حداقل یک پروژه عملی هم با ایرفلو پیش ببریم. امیدوارم براتون مفید باشه.
آپاچی ایرفلو چیست؟
یک کارخانه رو تصور کنید، کلی کارهای مختلف باید داخل انجام بشه. مثل ترکیب مواد، بستهبندی محصولات و ارسال. حالا یک مدیر خیلی منظم استخدام میکنیم که این کارها رو با برنامهریزی و هماهنگی بین بخشهای مختلف مدیریت کنه. ایرفلو دقیقاً همین مدیره هست ولی برای دنیای دیتا و برنامهنویسی!
ایرفلو یک ابزار متنباز از آپاچی هست که کمک میکنه کارهای پردازش داده، اتوماسیون و هماهنگی بین تسکها رو خیلی منظم و دقیق انجام دهیم. مثلاً بهش میگیم چه کارهایی با چه ترتیبی باید انجام بشه، اونم مثل یه کارگردان حرفهای، همه چیز رو مدیریت میکنه.
چیزی که ایرفلو رو خاص میکنه اینه که باهاش میتونیم گردش کار (Workflow) بسازیم و بررسی کنیم چه کارایی در چه زمانی اجرا شدن، کدومشون موفق بوده و اگه خطایی پیش اومده، راحت اشکالیابی کنیم. به نظرم خوبه یکم در مورد سیستم مدیریت گردش (جریان) کار یا WMS چیزهایی بدونیم.
سیستم مدیریت جریان کار یا WMS چیست؟
آپاچی ایرفلو دقیقاً یک سیستم مدیریت جریان کار یا Workflow Management System (WMS) هست. یک WMS سیستمیه که به ما کمک میکنه تا یک سری فرآیندها یا کارهای مرتبط به هم رو برنامهریزی، اجرا، نظارت و مدیریت کنیم. این فرآیندها میتونن شامل هر چیزی باشن، مثل:
- پردازش دادهها
- اجرای اسکریپتها
- هماهنگسازی کارها بین سرویسهای مختلف
- مدیریت فرایندهای ETL (استخراج، تبدیل و بارگذاری داده)
- و حتی خودکارسازی کارهای تکراری توی سیستمهای مختلف
چرا WMS مهمه؟
فرض کنین در یک شرکت دادهمحور کار میکنیم و باید هر روز صبح چندین گزارش از منابع مختلف جمعآوری کنیم و بعد از اعمال یک سری پردازشها، خروجی رو برای تیمهای مختلف بفرستیم. بدون یک سیستم مدیریت جریان کار، باید کلی اسکریپت دستی بنویسیم و اجرا کنیم که در اکثر مواقع کلی خطا پیش میاد و یه جای کار گیر میکنه.
حالا با یک WMS مثل Apache Airflow، میتونیم این کارها رو بهصورت خودکار و وابسته به هم اجرا کنیم، وضعیت اجرای تسکها رو مانیتور کنیم و اگر مشکلی پیش بیاد، راحت بررسی داشته باشیم.
ویژگیهای کلیدی یک WMS خوب
تا امروز چندین ابزار خوب برای یک WMS معرفی شده، اما یک WMS خوب باید چه ویژگیهایی داشته باشه؟
✅ ارتباط با ابزار: ابزاری که انتخاب میکنیم باید بتونیم باهاش ارتباط برقرار کنیم. مثلاً یک محیط گرافیکی خوب در تعریف تسکها و ترتیبشون به ما خیلی کمک میکنه. همچنین اینکه خیلی از برنامهنویسان حرفهای با خط فرمان راحت هستند. پس اگر خط فرمان هم پشتیبانی کنه عالیه. شاید بخوایم ابزار را داخل اپلیکیشن خودمون کنترل کنیم، بنابراین اگر بتونیم ازش API هم بگیریم که دیگه حرف نداره.
✅ برنامهریزی و زمانبندی: این ابزار باید در بحث برنامهریزی و زمانبندی تسکها محدودیت نداشته باشه به گونهای که وابسته به زمانبندهای بیرونی مثل لینوکس نباشیم و امکانات خوبی رو در اختیار ما بذاره. همچنین در تعریف جریان کاریهای مختلف منعطف باشه و دستمون رو باز بذاره.
✅ مقیاس پذیری: بحث مقیاس پذیری در پروژههای توزیع شده و بزرگ بسیار مهم است. ابزاری را باید انتخاب کنیم که مقیاس پذیر باشه و بتونیم روی چندین نود بیاریمش بالا و بتونیم تسکها رو موازی انجام دهیم.
✅ توسعه پذیری: منظورم از توسعه پذیری این هست که بتونیم به امکانات ابزار اضافه کنیم. مثلاً منو یا قابلیتی که مخصوص به خودمون هست رو بهش اضافه کنیم. در واقع یک سیستم مدیریت پلاگین قوی داشته باشه.
✅ مانیتورینگ و گزارشدهی: در ابزارها بحث مانیتورینگ، لاگ و گزارشدهی بسیار مهم است. بنابراین ابزاری که انتخاب میکنیم باید متریکهای خوبی برای مانیتور کردن و گزارش گرفتن در اختیار ما قرار بده. همچنین اگر سیستم هشدار دهی هم داشته باشه که خیلی خوبه، به محض اینکه تسکی درست اجرا نشه، به طرق مختلف هشدار ارسال کنه.
✅ مدیریت تسکها: این ابزار باید بتونه تسکها رو مدیریت کنه. مثلاً اگر قراره اجرای تسکی ۳ دقیقه طول بکشه، راس سه دقیقه تسک رو به اتمام برسونه (SLA) و امکان اولیتدهی به تسکها رو داشته باشه. یا مثلاً امکان Catch Up یا Back Fill داشته باشه یعنی یک تسک رو از دو ماه پیش تا امروز به صورت روزانه اجرا کنه. همچنین انتظار داریم که قابلیت Tunable Retries برامون فرآهم باشه که مثلاً مشخص کنیم برای اجرای یک تسک اگر خطا یا گیری پیش اومد، بعد از اینکه ۵ بار تلاش کردی، اونوقت به ما هشدار بده و برای تسک عدم موفقیت صادر کن.
✅ قابلیتها و توابع: مهندسان داده و برنامهنویسان عموماً از یکسری توابع زیاد مصرف میکنند. اصطلاحاً توابع پرمصرفی هستند و خیلی کم پیش میاد که نیاز به توابع خاصی وجود داشته باشه. بنابراین ابزاری که انتخاب میکنیم اگر مجموعه غنی از توابع رو داشته باشه عالیه.
✅ جامعهی فعال: این یک اصل مهم در انتخاب ابزار هست. وقتی میخواهیم ابزاری رو انتخاب کنیم، حتماً باید جامعهی فعالی داشته باشه که در صورت بروز مشکل، سریع نواقص برطرف گردد. یا اگر مسئله و سوالی داشتیم بتونیم از تجربیات سایر مهندسان استفاده کنیم. عموماً در دنیا، گیت و فرومهای مربوط به ابزار رو بررسی میکنن اما در ایران علاوه بر گیت و فرومها، سایر شرکتها هم مهم هستند 😐. مثلاً اگر شرکت بزرگی تا حالا سراغ ایرفلو نرفته، شرکت دیگه هم یا سراغ این ابزار نمیره یا با ترس میره البته این دغدغه به دلیل عدم دسترسی سریع به متخصص، برای شرکتها مهم شده. به نظر من اگر ابزاری گیت و فروم قوی داشته باشه، دیگه دغدغهای جایز نیست و شرکتها نباید نگران باشند. 😅
بررسی WMS های معروف
خب حالا که خوب با WMS و ویژگیهای یک WMS خوب آشنا شدیم، بیاییم و ابزارهای معروف این حوزه رو باهم مقایسه و بررسی کنیم.
پس متوجه شدیم، یک WMS سیستمی است که کمک میکنه مجموعهای از کارها (تسکها) رو بهشکل برنامهریزیشده، خودکار و وابسته به هم اجرا کنیم. در جدول بالا مقایسهی ابزارهای سیستم مدیریت جریان کار رو باهم بررسی کردیم. آپاچی ایرفلو یکی از قویترین و کاربردیترین ابزارهای WMS است که با استفاده از DAG (Directed Acyclic Graph) های تعریف شده، متوجه میشه که چه کارهایی و به چه ترتیبی باید انجام بشن. نکته مهمی که ابزار ایرفلو رو نسبت به بقیه ابزارها متمایز کرده، قابلیت برنامهنویسی (با زبان پایتون) تسکها و جریانکارهاست. این قابلیت به ما انعطاف زیادی میده و دست ما رو در تعریف جریان کاریهای مختلف باز میذاره البته برخی از ابزارها تلاش کردهاند با کانفیگها این انعطاف پذیری را فراهم نمایند.
مفاهیم پایهای ایرفلو
قبل از اینکه با ایرفلو کار کنیم، باید با چند مفهوم کلیدی آن آشنا شویم. این مفاهیم در قلب Airflow قرار دارند و درک آنها کمک میکند که گردشکارها (Workflows) را به درستی درک و مدیریت کنیم.
دَگ یا DAG (Directed Acyclic Graph) چیست؟
به زبان ساده دَگ یا DAG یک مفهوم مهم در ایرفلو هست. یک DAG مجموعهای از کارها (تسکها) است که به شکلی خاص و بدون حلقه به هم متصل شدهاند. در واقع هر DAG شامل چندین تسک (Task) است که طبق یک زمانبندی (Schedule) مشخص اجرا میشوند. مثلاً فرض کنید میخواهیم یک سیستم پردازش خودکار لاگ راهاندازی کنیم. کارهای ما به این صورت میشوند:
- جمعآوری لاگها (Collect Logs): دریافت لاگها از منابع مختلف (NGINX، Apache، سیستمعامل و غیره)
- پاکسازی لاگها (Clean Logs): حذف دادههای غیرضروری و فرمتبندی لاگها
- تحلیل لاگها (Analyze Logs): بررسی الگوهای رایج، پیدا کردن خطاها، تشخیص درخواستهای مشکوک
- ذخیره لاگهای پردازششده (Store Logs): ذخیره در Elasticsearch یا پایگاه داده برای دسترسی سریع
- ایجاد هشدار (Trigger Alert): اگر ارورهای زیادی در مدت کوتاه شناسایی شد، ارسال هشدار به تیم DevOps
رابطه بین این مراحل چگونه است؟
✅ باید اول لاگها را جمعآوری کنیم تا بتوانیم بقیه مراحل را انجام دهیم.
✅ بعد باید لاگها را تمیز کنیم تا اطلاعات اضافی حذف شوند.
✅ سپس میتوانیم آنها را تحلیل و مشکلات احتمالی را پیدا کنیم.
✅ وقتی تحلیل کامل شد، ذخیرهشان میکنیم تا بعداً در داشبورد استفاده شوند.
✅ در نهایت، اگر مشکلی شناسایی شد، هشدار ارسال میشود.
پس این یک DAG است، چون:
- هر مرحله به مرحله قبلی وابسته است. (نمیتوانیم تحلیل را قبل از جمعآوری لاگها انجام دهیم).
- حلقه ندارد. (به مرحله قبلی برنمیگردد).
- میتوانیم وابستگیها را مشخص کنیم. (مثلاً هشدار فقط وقتی اجرا شود که تحلیل، خطای مهمی را پیدا کرده باشد).
تصویر این DAG به صورت زیر خواهد بود:

دَگ (DAG) مربوط به مثال پردازش لاگها
تسک (Task) چیست؟
تسکها کوچکترین واحد اجرایی هستند که در قالب DAGها (گرافهای جهتدار بدون حلقه) سازماندهی میشود. در واقع هر تسک یک نود در DAG هست که نمایانگر یک مرحله از جریان کاری است و ترتیب اجرای آنها با تعریف وابستگیهای بالادستی و پاییندستی مشخص میشود. تسکها انواع دارند:
-
اُپراتورها (Operators): قالبهای از پیش تعریفشده یا الگوی کلی برای اجرا کردن یک کار هست. با استفاده از اپراتورها میتونیم تسکهای مختلف را در DAG ایجاد کنیم. در ادامه اُپراتورها را بیشتر بررسی خواهیم کرد. تسک (Task) یه اجرای واقعی از اُپراتور هست که داخل DAG قراره اجرا بشه.
-
سنسورها (Sensors): سنسورها زیرمجموعهای از اپراتورها هستند که منتظرند یک رویداد رخ دهد. مثلاً چک میکنن یک فایل وجود دارد یا خیر.
-
TaskFlow که با دکوریتور @task مشخص میشوند: میتونیم توابع پایتونی رو با استفاده از دکوریتور @task به تسک تبدیل کنیم. اگر نخواهیم از دکوریتور @task استفاده کنیم، باید یک PythonOperator تعریف کنیم و داخل آن تابع پایتونی را فرآخوانی نماییم.
Task Instances چیست؟
تسک اینستنس (Task Instances) رو با یک مثال توضیح میدهم. فرض کنین یک دَگ (DAG) داریم که هر روز اجرا میشه و یک تسک به نام extract_data داره که دادههای یک دیتابیس رو استخراج میکنه. حالا این دَگ از ۱ فروردین تا ۳ فروردین اجرا شده. پس ۳ تا Task Instance برای extract_data داریم، چون این تسک در ۳ تاریخ مختلف اجرا شده است. به زبان ساده هر بار که یک دَگ اجرا میشه، یه نمونه (Instance) از هر Task در اون دَگ (DAG) ساخته میشه که بهش میگیم Task Instance.
هر Task Instance در ایرفلو یک وضعیت خواهد داشت که میتونیم در UI ایرفلو این وضعیت را مشاهده کنیم. وضعیتها مانند ✅ موفق (Success)، 🟢 در حال اجرا (Running)، ⚫ منتظر اجرا (Queued)، 🔴 ناموفق (Failed)، ⚪ رد شده (Skipped) و غیره.
اُپراتور (Operator) چیست؟
همانطور که قبلاً اپرتورها را تعریف کردیم، اُپراتورها در واقع نوعی تمپلیت و الگوی کلی برای اجرا کردن یک تسک هست. یک اُپراتور در ایرفلو مثل یک دستورالعمل از پیش تعریفشده است که مشخص میکنه چه کاری باید انجام شود. مثلاً:
- اُپراتور PythonOperator: اجرای یک اسکریپت پایتون را مشخص میکند.
- اُپراتور BashOperator: اجرای یک دستور لینوکس را توضیح میدهد.
- اُپراتور HttpOperator: ارسال یک درخواست به API را تعیین میکند.
به بیان سادهتر اُپراتور فقط یک قالب برای اجرای یک نوع کار خاص است. ایرفلو مخزن غنی از انواع اُپراتورها را در خود دارد. همچنین میتونیم به صورت شخصی سازی شده اُپراتور جدید تعریف و پیاده سازی کنیم.
هوک (Hook) در ایرفلو چیست؟
گاهی ممکنه در اُپراتورها نیاز باشه به منابع خارجی متصل بشیم. اگر بخواهیم در ایرفلو به منابع خارجی متصل بشیم، هوکها به ما کمک میکنند. هوک (Hook) در ایرفلو یک رابط اتصال برای برقراری ارتباط با سیستمهای خارجی مثل دیتابیسها، APIها و سرویسهای ابری هست. مثلاً فرض کنید یک DAG داریم که باید دادههایی رو از یک API خارجی بخونه و اونها رو در دیتابیس MySQL ذخیره کنه. در این سناریو، دو تا هوک میتونن به ما کمک کنن:
✅ HttpHook: برای ارتباط با API خارجی
✅ MySqlHook: برای نوشتن دادهها در دیتابیس
مزیت اصلی هوکها اینه که اتصال به سیستمهای خارجی رو استاندارد میکنن و نیازی نیست داخل هر تسک از صفر یک اتصال جدید بنویسیم.
معماری ایرفلو
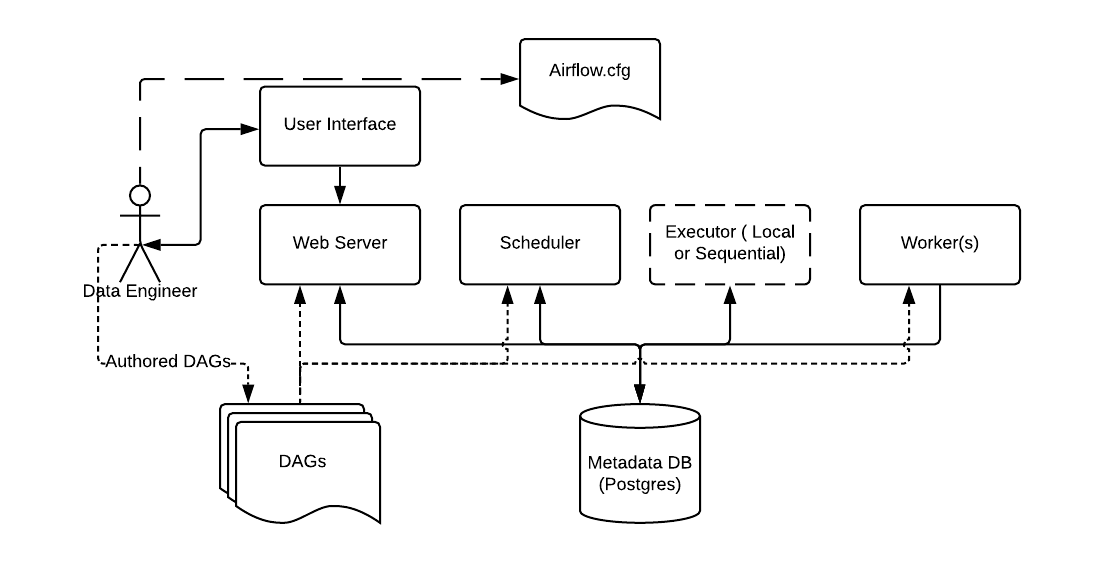
معماری ایرفلو – منبع تصویر: https://airflow.apache.org/docs/apache-airflow/2.0.1/concepts.html
ابتدا باید با استفاده از فایل کانفیگ (Airflow.cfg) که شامل تنظیمات ابزار ایرفلو هست رو نصب و راه اندازی کنیم. بعد از راه اندازی باید شروع کنیم و DAGهای خودمون رو بنویسیم. در ادامه یاد میگیریم چطور دَگ بنویسیم اما به صورت خلاصه اُپراتورهای مورد نیاز مسئله و وابستگیهای اُپراتورها رو در یک فایل py کد نویسی میکنیم. این py فایل حاوی دَگ ما هست که برای معرفی به ابزار ایرفلو کافی است در فولدر DAGs با کپی و پیست قرارش بدیم. بعد از چند ثانیه ایرفلو دَگ ما را شناسایی میکند و اقدامات لازم را انجام میدهد. پس ما یک py فایل آماده میکنیم که حاوی چند خط کد پایتونه و این فایل py را در فولدر DAGs منتقل میکنیم. حالا برای مدیریت دَگها و اجراهاشون باید با ایرفلو ارتباط بگیریم. این ارتباط از طریق رابط کاربری (User Interface) برای ما فرآهم شده است.
رابط کاربری ایرفلو هم به صورت صفحه وب با محیط گرافیکی است، هم API را پشتیبانی میکند و هم میتونیم با کامند با این ابزار ارتباط برقرار کنیم. یک وب سرور (Web Server) داریم که علاوه بر سِرو و پشتیبانی از رابط کاربری، تغییرات دَگها، اجراها و Workerها رو بررسی میکنه.
زمانبند (Scheduler) وظیفه ارسال تسکها به صف جهت اجرا را برعهده دارد. در واقع زمانبند با بررسی مداوم فایلهای دَگ، زمانبندیهای لازم را انجام میدهد. ما هنگام نوشتن فایل دَگ زمان اجرا را در py فایل مربوطه مشخص میکنیم و زمانبند مطابق با زمانبندیهای گفته شده در دَگها تسکها را برای اجرا به صفها ارسال میکند.
پایگاه داده متادیتاها (Metadata DB)، دیتابیسی است که دیتاهای داخلی ایرفلو در اون ذخیره میشه. این دیتاها شامل کاربران و دسترسیهاشون، دَگها و لیست تسکها، اجراهای اتفاق افتاده و هر دادهای که به دَگ و نیازمندیهای داخلی ایرفلو مربوط میشه. دیتابیس پیشفرض ایرفلو SQLite هست و میتوان این دیتابیس را تغییر داد اما نکتهای که داره اینه که باید دیتابیسی انتخاب کنید که از SQL Alchemy پشتیبانی کنه. چون ایرفلو با ORM و SQLAlchemy با دیتابیس تعامل میکنه.
اجرا کننده (Executor) در کنار زمانبند است و به نوعی مسئول اجرای تسکهاست. در واقع اجراکننده تصمیم میگیره که تسکها روی چه سیستمی و به چه صورتی اجرا بشن (روی همون سرور ایرفلو، در کلاستر، روی Kubernetes و غیره). اجراکنندهها انواع مختلفی دارند مثلاً:
- SequentialExecutor: همه تسکها رو یکییکی (سریالی) اجرا میکنه، بدون اجرای همزمان.
- LocalExecutor: چندین تسک رو بهصورت همزمان روی همون سروری که Airflow اجرا شده پردازش میکنه.
- CeleryExecutor: تسکها رو بین چندین سرور تقسیم میکنه (مناسب برای محیطهای توزیعشده).
- KubernetesExecutor: هر تسک رو در یک پاد (Pod) جداگانه روی Kubernetes اجرا میکنه.
- DaskExecutor: از Dask برای اجرای موازی تسکها استفاده میکنه (مناسب برای محاسبات سنگین دادهای).
وُرکرها (Workers) پراسس های اجرایی هستند که تسکها رو از صف برمیدارند و اجرا میکنن. ورکرها با سایر بخشهای ایرفلو مثل زمانبند، پایگاهداده متادیتا و غیره ارتباط دارند. بسته به اینکه Executor چه محیط را برای اجرا تعیین کرده باشد، ورکرها شروع به اجرای تسکها میکنند.
سوال: همانطور که گفته شد ایرفلو داره از صف استفاده میکنه. صف رو کی داره تامین میکنه؟ اگر جوابش رو میدونید در بخش دیدگاهها کامل توضیح بدید. ما در جلسات بعدی موقع نصب ایرفلو به این بخش خواهیم رسید.
متغیرها در ایرفلو
برخی مقادیر مثل apikey، پسورد یا مقادیر پیکیربندی ممکنه در چندین دَگ و تسک تکرار بشه. این مقادیر رو میتونیم به صورت ساده و ابتدایی داخل کد py فایل بذاریم (هارد کد کنیم) که کار خوبی نیست، میتونیم هم از متغیرها در ایرفلو استفاده کنیم. یکی از کاربردهای متغیرها اینه که اطلاعات مهم و حیاتی رو نیاز نیست داخل کدهای پایتون قرار بدیم. برخی از مزایای استفاده از متغیرها در ایرفلو عبارتند از:
✅ اگه یه مقدار (مثلاً نام یک مسیر یا کلید API) توی چندین دَگ استفاده بشه، بهجای تغییر در کل دَگها، فقط مقدار متغیر رو عوض میکنیم.
✅ برای مدیریت اطلاعات حساس (مثلاً توکنهای API) خیلی کاربردی هستن.
✅ دَگها رو پویاتر (Dynamic) و انعطافپذیرتر میکنن.
نکته مهمی که در متغیرهای باید رعایت کنیم این هست که متغیرها رمزنگاری نمیشوند بنابراین اطلاعات حساس مانند اتصال به دیتابیس رو نباید در متغیرها قرار بدیم. اتصال به دیتابیس رو باید در کانکشنها تعریف کنیم که در ادامه بررسی خواهیم کرد.
برای تعریف متغیرها هم میتونیم از محیط وب ایرفلو (منوی Admin بخش Variables) استفاده کنیم و هم از طریق خط فرمان (کامند).
کانکشن یا Connection چیست؟
کانکشنها در ایرفلو اطلاعات مربوط به اتصال به سرویسهای خارجی (مثل دیتابیس، APIها، و ابزارهای پردازش داده) رو ذخیره میکنن. به زبان ساده، کانکشنها راهی برای ذخیره و مدیریت اطلاعات ورود و آدرس سرویسهای خارجی هستن، تا نیاز نباشه توی هر دَگ مشخصات اتصال رو دستی وارد کنیم.
برای تعریف یک کانکشن مانند متغیرها، هم میتوانیم از محیط وب (منوی Admin و بخش Connections) استفاده کنیم و هم از طریق خط فرمان.
XCom چیست؟
اگر بخوایم دادهها را بین دو تسکمون جابهجا کنیم و یک تسک به تسک دیگر داده ارسال کند، XComها (Cross-Communication) به ما کمک میکنند. بدون ایکس کامها هر تسک در دَگ کاملاً جدا اجرا شده و نمیتونه نتیجه تسکهای قبلی که اجرا شده رو ببینه. این مقادیر داخل دیتابیس نوشته میشه پس حتماً دقت کنید که در ایکس کامها از مقادیر بزرگ استفاده نکنید.
Pool در ایرفلو چیست؟
برای اینکه این مفهوم رو توضیح بدم، بیاییم فرض کنیم یک دَگ داریم که ۱۰۰ تسک داره و همهی این تسکها یک API خارجی را صدا میزنند، اما اون API در تعداد درخواست همزمان محدودیت داره. یعنی اگر بیش از ۱۰ درخواست همزمان بهش برسه یا خطا میده یا بلاک میکنه. در اینجا اگر ۱۰۰ تسک با هم اجرا شوند، ممکنه API بلاک کنه. اینجاست که پول (Pool)ها میان به کمک ما. با کمک Pool در ایرفلو میتونیم تعداد تسکهای همزمان رو محدود کنیم.
به نظرم خوبه کمی در مورد نحوه کار Pool بدونیم. هر Pool یک تعداد مشخصی Slot داره و هر تسک که داخل اون Pool تعریف بشه، یک یا چند Slot اشغال میکنه.
-
Pool با ۱۰ اسلات (Slot): یعنی ده تسک همزمان اجرا میشن و تسک یازدهم صبر میکنه تا یکی از تسکهای قبلی تموم بشه. اگر یک تسک بیشتر از یک اسلات بخواهد، این تسک بهجای یک اسلات، دو اسلات اشغال میکنه و باعث میشه بقیه تسکها دیرتر اجرا بشن.
حالا که بحث اسلات (Slot) شد، این مفهوم هم با یک مثال توضیح بدم. فرض کنین در یک رستوران کار میکنیم و فقط ۵ میز خالی داریم. هر مشتری که میاد، یک میز (Slot) را اشغال میکنه. وقتی ۵ میز پر بشن، مشتری جدید باید صبر کنه تا یکی از میزها خالی بشه. میزها در این مثال در واقع اسلاتها (Slots) هستند.
به زبان ساده هر تسک برای اجرا نیاز به یک یا چند اسلات داره و تا وقتی که Slot خالی توی اون Pool وجود نداشته باشه، تسک در وضعیت انتظار (queued) میمونه. در واقع یک اسلات (Slot) Slot به معنی ظرفیت پردازشی محدودی هست که برای اجرای همزمان تسکها تعیین میکنیم. بنابراین موقع تعریف اُپراتور میتونیم مشخص کنیم تسک مربوط به اُپراتور در چند اسلات اجرا شود.
سوال: ما در دَگها میتونیم حداکثر تسک همزمان (concurrency) رو تعیین کنیم، دیگه چرا از Pool استفاده کنیم؟
جواب: concurrency تعیین میکنه حداکثر چند تسک همزمان در یک دَگ اجرا بشن یعنی در سطح دَگ (DAG) هستش اما Pool در سطح کل ایرفلو اعمال میشه و منابع محدود رو بین چندین DAG مدیریت میکنه.
زمانهای اجرا در ایرفلو
زمان Execution Date در ایرفلو
برچسبی که نشون میده این اجرا مربوط به چه تاریخی از دادههاست. این زمان کمی گیج کننده هست چون ایرفلو همیشه دَگ رو با برچسب تاریخ قبلی اجرا میکنه. مثلاً اگر execution_date=2025-02-20 باشد، یعنی این اجرا مربوط به دادههای ۲۰ فوریه هست، با وجود اینکه اگر دَگ در ۲۱ فوریه اجرا شده باشه.
📌 مثال ساده: دَگ (DAG) روزانه
فرض کنین یک دَگ داریم که هر روز اجرا میشه (@daily) و دادههای روز قبل رو پردازش میکنه. حالا تصور کنین که امروز ۲۱ فوریه ۲۰۲۵ هست. اگر ایرفلو امروز این DAG رو اجرا کنه، Execution Date چی میشه؟
✅ Execution Date: 2025-02-20
✅ زمان واقعی اجرا: ۲۰۲۵-۰۲-۲۱
دلیلش اینه که این DAG دادههای روز ۲۰ فوریه رو پردازش میکنه، پس Execution Date بیست فوریه خواهد بود، حتی اگر ۲۱ فوریه اجرا بشه. در واقع به نظر من یه جورایی Execution Date، شناسهی اجرای دَگ هست، نه زمان واقعی اجرا!!! 😵
در استک اُور فلو (stackoverflow) هم در موردش بحث شده، وقت داشتید بخونید (اینجا کلیک کنید).
سایر زمانهای اجرا در ایرفلو
- زمان Start Date: دوتا Start Date داریم. یکی مربوط به دَگ هست که بیانگر تاریخی است که DAG از اون زمان به بعد اجازه اجرا داره. این مقدار رو نباید تغییر داد، چون روی Backfill و اجراهای دَگ تاثیر داره. یکی هم مربوط به Task هست که مشخص میکنه، تسک چه زمانی واقعا شروع به اجرا کرده است.
- زمان End Date: زمانی است که تسک به پایان میرسه.
- زمان Duration: مدتزمانی که تسک در حال اجرا بوده (End Date – Start Date).
- زمان Queuing: زمانی که تسک توی صف منتظر بوده تا اجرا بشه.
- زمان Total Runtime: مجموع زمان Queuing + زمان Duration.
خلاصه نصب ایرفلو
ابتدا باید چک کنیم که نسخه پایتون سیستم عامل ۳.۷ یا بالاتر باشه. بعد باید در متعیرهای محلی، مکان ایرفلو رو مشخص کنیم که ایرفلو بدونه باید دگ ها رو از کجا بخونه. با دستور pip install apache-airflow ایرفلو رو نصب میکنیم. اگر قصد داریم ایرفلو از دیتابیس پیشفرض خودش استفاده کنه، کافیه دستور airflow db init رو اجرا کنیم تا اقدامات و جداول اولیه این ابزار ایجاد گردد.
در قدم بعدی باید وب سرویس ایرفلو رو با دستور airflow webserver –port 8080 بیاریم بالا. وقتی وب سرور راه اندازی شد در مسیر http://localhost:8080 میتونیم UI ایرفلو رو ببینیم. در مرحله آخر هم با دستور airflow scheduler زمانبند (Scheduler) را راهاندازی میکنیم تا بتونه دَگها رو بررسی و تسکها رو اجرا کنه.
تا اینجا تونستیم خیلی ساده ایرفلو رو نصب کنیم (در جلسه بعدی مفصل روی نصب ایرفلو کار خواهیم کرد). همانطور که قبلاً گفتم باید دَگهامون یا همون فایلهای پایتونی رو در پوشه DAGهای ایرفلو قرار دهیم. با اینکار زمانبند، تک تک این فایلها رو بررسی و زمانبندی میکنه، و تسکهای مربوطه را در صف جهت اجرا قرار میدهد.
از اینکه این مطلب آموزشی رو مطالعه کردید سپاسگزارم. 🙏 امیدوارم تونسته باشم شما رو با ایرفلو آشنا کنم. تلاش کردم ساده و کاربردی مفاهیم ایرفلو رو توضیح بدم. سوالی براتون پیش اومده میتونید از این بخش (کلیک کنید) یعنی پایین صفحه از من بپرسید. سعی میکنم در اسرع وقت پاسخ شما رو بدم.
منابعی که میتونید مطالعه بیشتر داشته باشید:

